
The Social Code: Evaluation of the Use of LLM-Based Agents for Social Simulation
Published:

Can large language models predict real world network connections?
Context
The emergence of human-like behavior in Large Language Models (LLMs) has inspired several research efforts to evaluate LLM agents in studies of human behavior. This project evaluates the reliability of using LLM agents to predict social relationships. By building LLM agents based on real network datasets, we are able to access how well LLMs reproduce real networks at the edge level, rather than focusing solely on the overall network structure.
- Conducted at: Network In Context Lab, U.S.
- Supervisors: Byungkyu Lee (New York University) and David Broska (Stanford University)
- Project Type: Research project initially developed as coursework and later extended in a research lab.
Contribution
- Compared to human experiments, LLM-based social simulations are more affordable, eliminate the risk to human participants, and are less time-consuming

- When evaluating simulation results, previous studies focus on the overall network structure.
- In contrast, we evaluate edge-level accuracy using real-world datasets to provide deeper insights into prediction reliability.

Method: Data-Grounded Simulation Approach
- Dataset: Indian village microfinance dataset
- 77 Indian villages
- Recorded the personal relationships of villagers(e.g. Who would you borrow money from? Ask for advice? … etc.)
- Recorded individual attributes: gender; caste, mother tongue … etc.)
- Preprocessing
- Find all possible pair of connections between any two villagers:\((V_i, V_j)\)
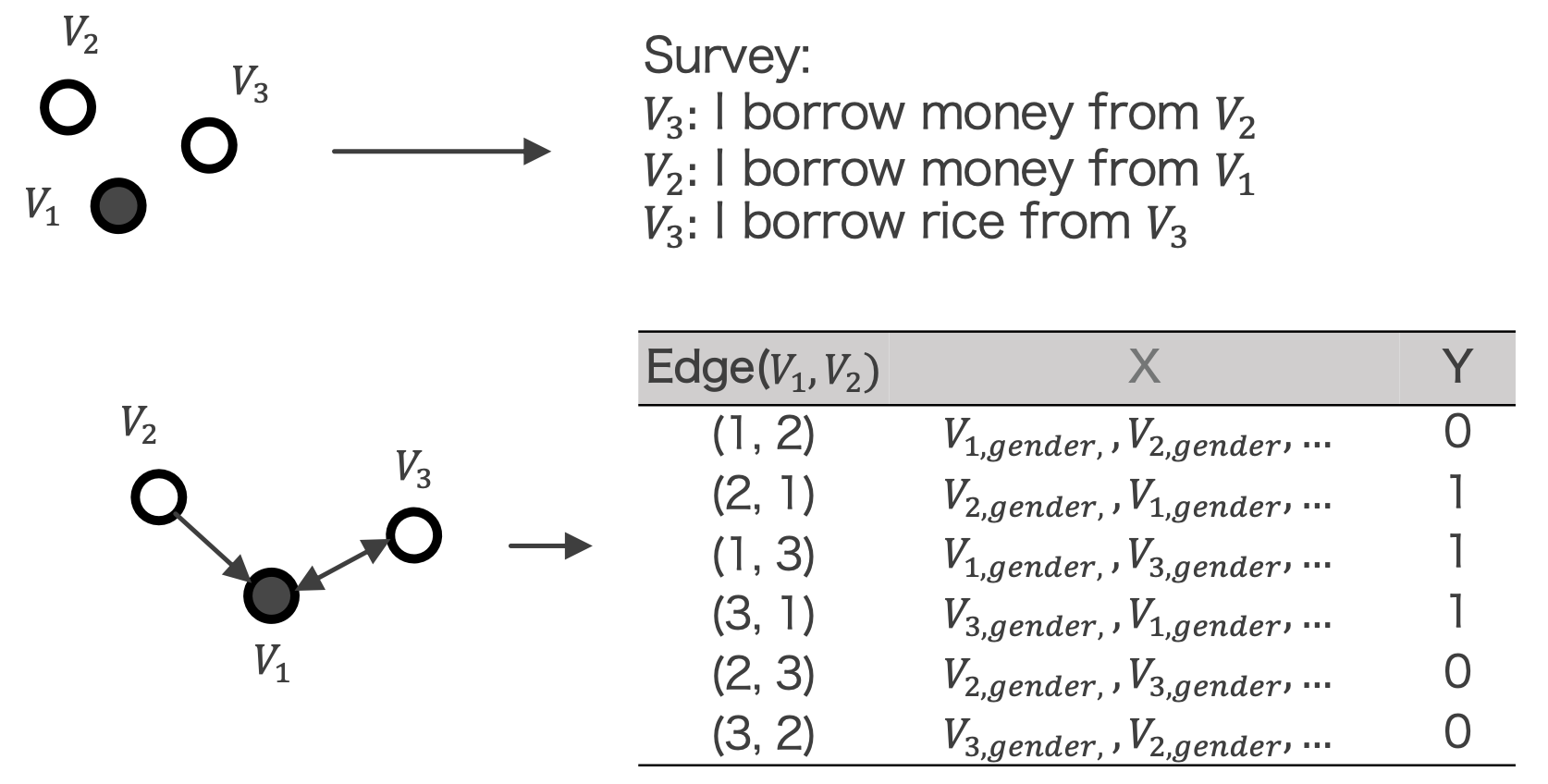
- Find all possible pair of connections between any two villagers:\((V_i, V_j)\)
- Identified influential variables affect the edge formation
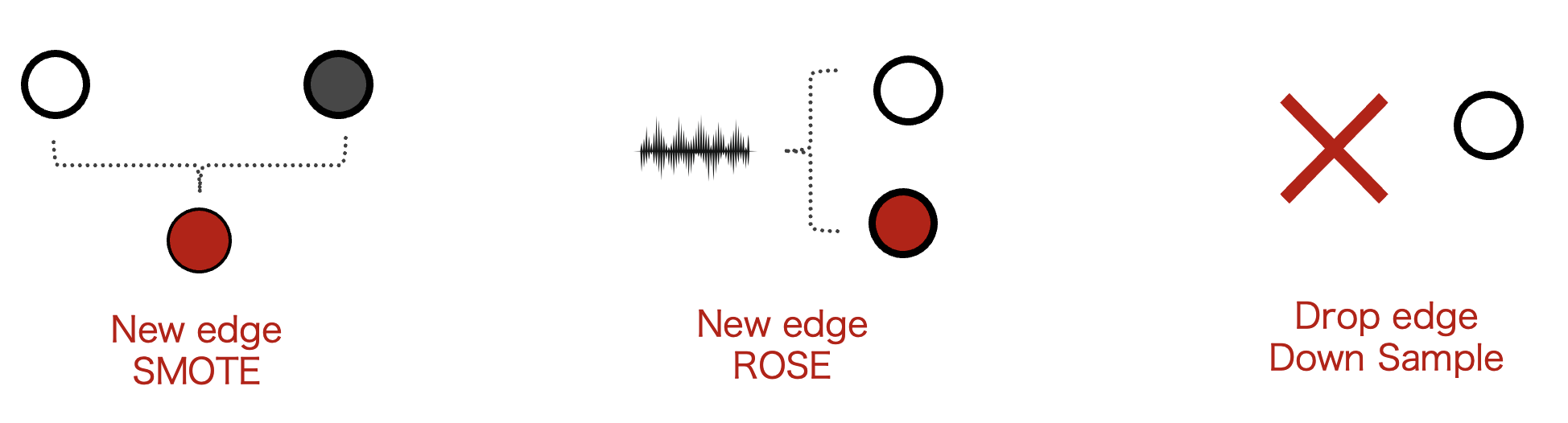
- Since the number of not exist edges is much more the existed edge, we applied balance method to adjust training dataset for preventing bias prediction
- SMOTE: Generate new edge (Y=1)
- Selected a random edge
- Find the sample’s nearest nearest KNN neighbors in features space
- Generate a new edge between them
- ROSE: Generate new edge (Y=1)
- Selected a random edge
- Create a small noise according to data distribution
- Generate a news edge
- Down Sampled: drop not existed edge (Y=0)
- Selected a random not existed edge
- Drop it
- SMOTE: Generate new edge (Y=1)
- Constructed a machine learning pipeline with logistic regression to identify influential demographic factors
- Y: if the edge exist
- X: demographic features of \(𝑉_𝑖, 𝑉_𝑗\) 1. Conduct Simulation: Asking LLMs predict network ties
- We applied global, local, and sequential methods, which have been validated[1] in predicting network structures identical to general human network:
- Global: Make entire network at once
# Sample prompt You wil be provided a list of people in the network. Please provide a list of friendship pairs in the format ID, 1. Woman, Asian, 54, HINDUISM 2. Man, White, 18, HINDUISM 3. Woman, Black, 39, HINDUISM - Assign one persona at a time, no network info
# Sample prompt You are a Woman, age 23, HINDUISM, You are joining a social network. Which of these people wil you become friends with? 1. Woman, Asian, 54, HINDUISM 2. Man, White, 18, HINDUISM 3. Woman, Black, 39, HINDUISM - Sequential: Similar with the local method, but add the network information
# Sample prompt You are a Woman, age 23, HINDUISM, You are joining a social network. Which of these people wil you become friends with? 2. Woman, Asian, 54, HINDUISM, 12 friends Man, White, 18, HINDUISM, 5 friends Woman, Black, 39, HINDUISM, 16 friends
- Testing The Number of Attributions
- Additionally, we explored whether using more demographic features during simulation would enhance edge prediction performance in the network.
- We tested this by using the top 2, 4, 6, 8, and 11 demographic features.
Results
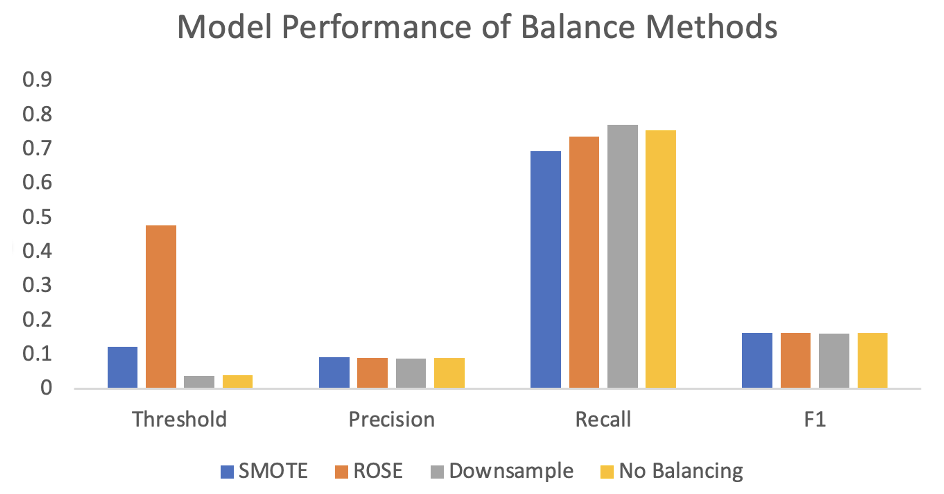
Balance Methods Evaluation
- Balance Methods Evaluation
- All methods have similar precision, F1 and recall.
- SMOTE have highest overall F-1 score
- Logistics Model Applied SMOTE on Predicting edges in the village networks
Identifying Influential Attributions in Real Dataset
- Rank from the most influential variable to the least influential variables:
- Caste
- Religion
- Gender
- Mother
- Tongue
- If villager have savings
- Ration card ownership
- Election card ownership
- Ration card classify
- Speak English or not
- If villager participate SHG or not
- Social Status
![]()
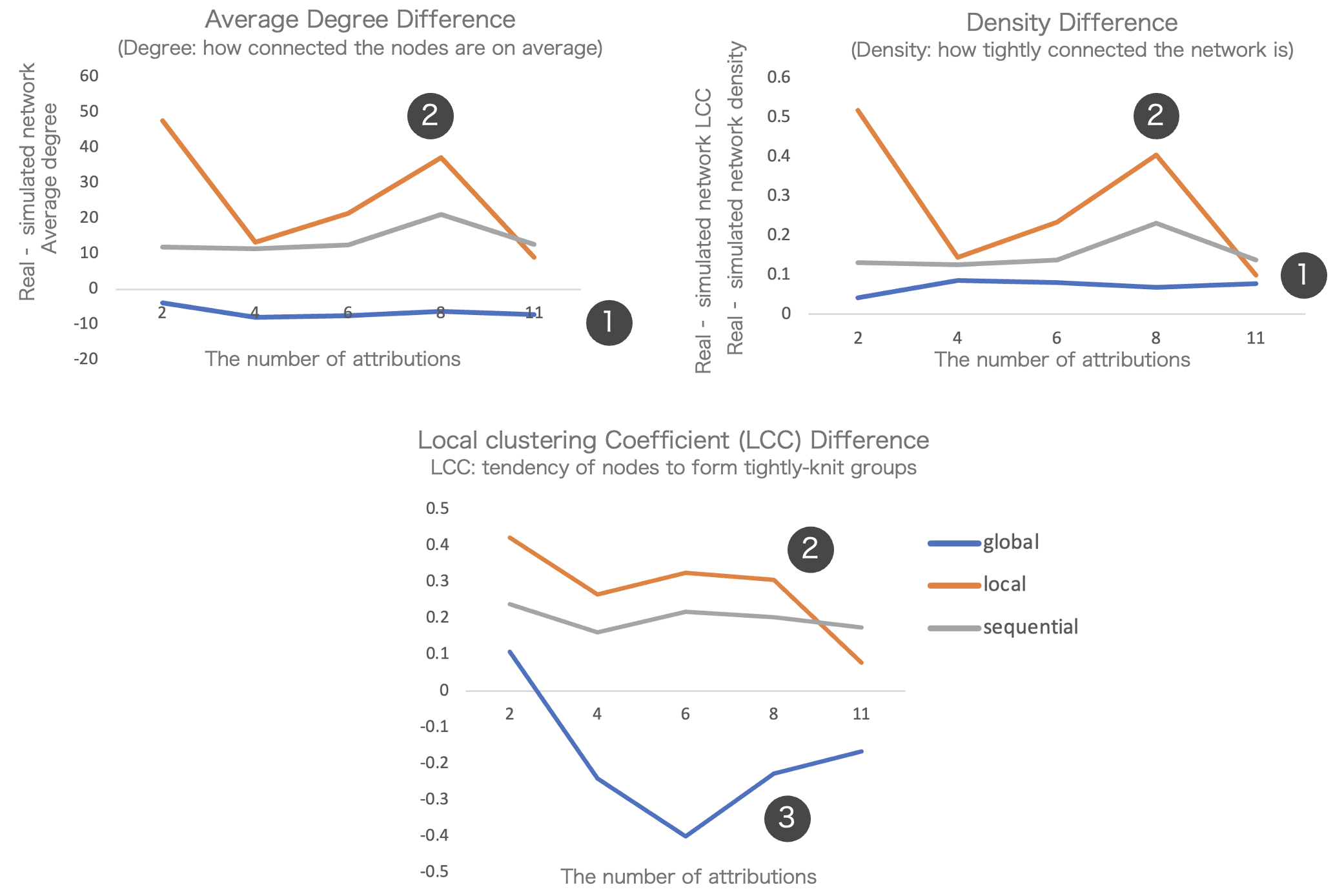
Comparison of Simulated and Real Network Graph At Structural Features
- Overall, the network generated by the global method is closest to the real network in terms of density and average degree
- Local method demonstrates highest difference in 3 matrices, indicating poor performance
- However, the global method performs the worst when evaluated based on the local clustering coefficient.
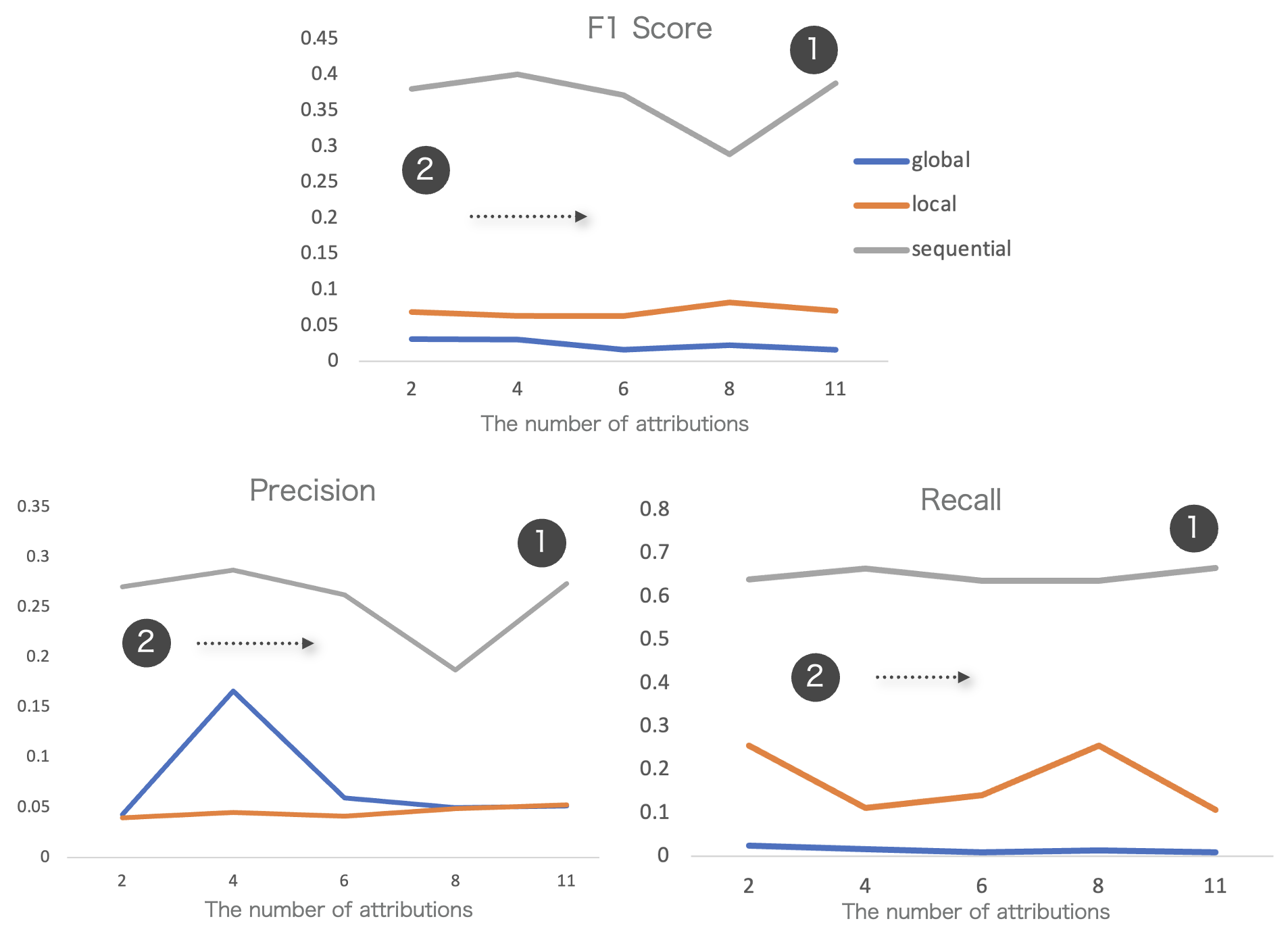
Comparison of Simulated and Real Network Graph At Edge Level
- The sequential method could achieved nearly 30% of precision, clearly outperforms others
- Adding attribution is not helpful: The precision, recall, and F1 scores showed no significant improvement as more attributes were added.
Key Insight
Generated structurally similar networks does not guarantee accuracy. While LLMs can generate structurally similar networks to real-world data, edge-level accuracy remains a challenge. This highlights potential risks in relying solely on LLM-based predictions for human-like social simulations.
Reference
[1] Chang, S., Chaszczewicz, A., Wang, E., Josifovska, M., Pierson, E., & Leskovec, J. (2024). LLMs generate structurally realistic social networks but overestimate political homophily. arXiv preprint arXiv:2408.16629.